1. docker 端口映射 防火墙设置
docker 需要映射以下端口,并开启云服务防火墙(例如你的是阿里云,那你可以搜索阿里云 防火墙设置) docker 端口映射:
- hadoop2 为例:
-
50070[web ui端口 pyspark连接不需要]
-
50010[数据节点端口]
-
50075[数据节点webui 端口]
-
8020[dfs存储端口]
补充说明如果使用的hadoop3 请调整对应的端口号为hadoop3中的端口号
- hive2 开放端口:
- 9083[元数据端口]
- 10000[hive jdbc 访问端口
- pyspark连接不需要]
下面附加hadoop2 hdfs端口相关的配置说明, hadoop3 的参考官方配置 https://apache.github.io/hadoop/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml
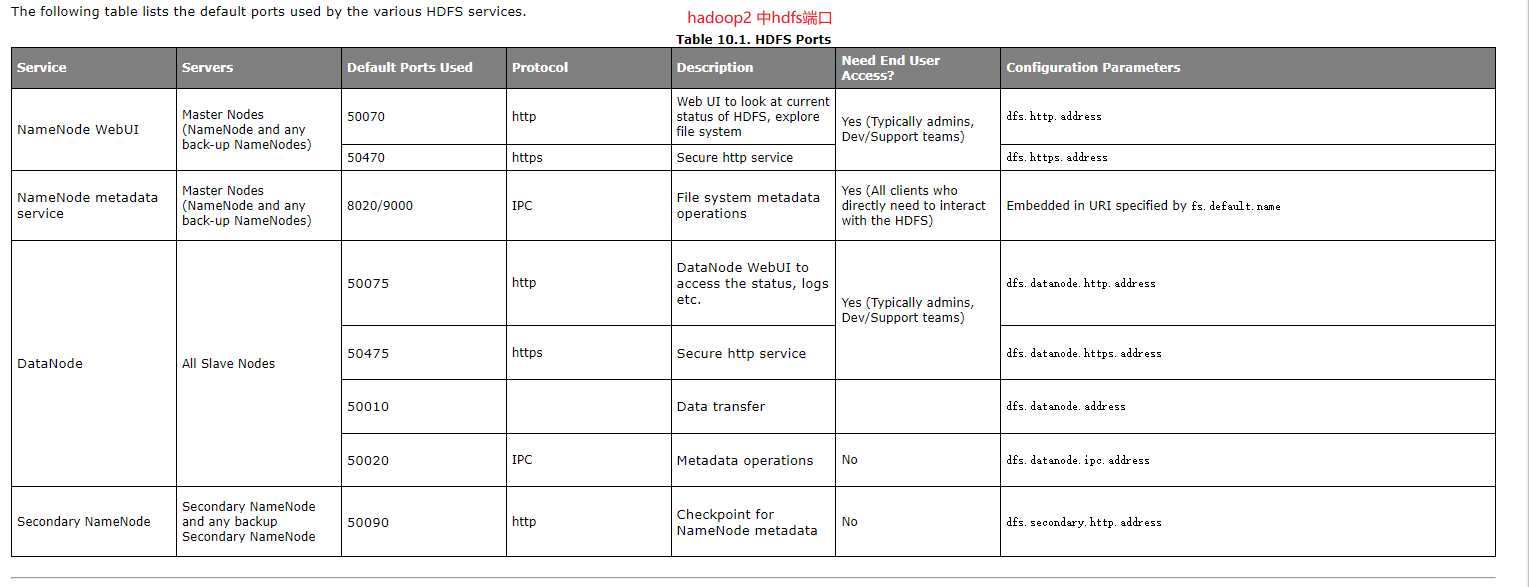
2. 映射端口说明
pyspark 连接hive 需要先连接hive的元数据库,然后再通过hdfs客户端连接hdfs来获取文件数据, 而客户端要先经过namenode获取datanode地址列表. 由于hadoop基于docker搭建的 而里面的都是docker内网地址. 所以我们需要做地址映射
3. 配置本地hosts 映射
81.x.x.x 是你的云服务公网地址
* 1. 映射你的hive元数据host 例如 81.x.x.x namenode
* 2. 映射你的namenode元数据host 例如 81.x.x.x namenode
* 3. 映射你的datanode的host,注意这个host是你的webui中呈现的host 看下嘛贴图. 如果datanode有几个那么你就需要映射几个. 映射: 81.x.x.x 0e35912a1c97
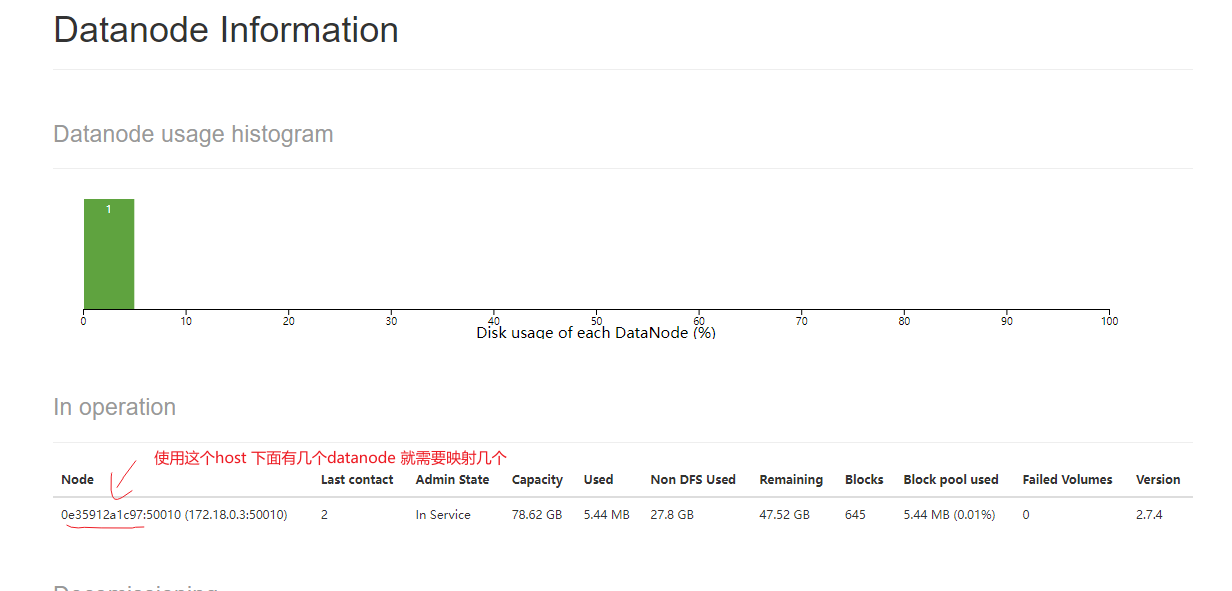
4.. pyaprk代码示例
注意这个里面的一些关键点 1. 环境变量HADOOP_USER_NAME 可能需要我们配置 2. spark.hadoop.dfs.client.use.datanode.hostname 解决namenode返回的是内网地址问题不能访问的问题,注意要配合我们上面的datanode地址映射使用
# pyspark版本 3.1.2 hadoop版本2.7.4 hive版本2.3.2
from pyspark.sql import SparkSession
import os
# 如果连接过程提示用户权限问题. 我们可以设置这个环境变量来指定hdfs用户
# 可以先不指定,有问题再指定
os.environ['HADOOP_USER_NAME']='root'
if __name__ == '__main__':
# 1- 创建 SparkSession对象: 支持与HIVE的集成
spark = (SparkSession
.builder
.master("local[*]")
.appName("insurance_main")
.config("spark.sql.warehouse.dir", "hdfs://namenode:8020/user/hive/warehouse") # 必须设置 设置数仓位置
.config("hive.metastore.uris", "thrift://namenode:9083") # 必须设置 设置metastore的位置
.config('spark.hadoop.dfs.client.use.datanode.hostname','true') # 设置客户端访问hdfs可以使用hostname来访问,配合本地hosts映射来完成对于datanode数据节点的访问
.enableHiveSupport() # 开启hvie支持
.getOrCreate())
spark.sql("select * from default.spark_test").show()声明 如果转载请注明出处. 如果有疑问也可以留言我的站点邮箱
0